前言 这个样本是上周日在“软件赛区域赛”中遇到的,当时使用 angr 拿过往针对 arm64 的反混淆脚本改了一下,勉强能看,事后觉得不够优雅,遂配合 AI 以开发 BinaryNinja 插件的方式,以一种更优雅的方式解决了这个混淆。
样本观察 以我对各种混淆的了解,这个题目的混淆应该使用的是 goron ,使用了间接跳转、间接函数调用、间接全局变量引用、字符串(C string)加密、过程相关控制流平坦混淆,也算是“拉满了”,不过总归是个开源的,单从强度上来说在这个 AI 时代其实谈不上高,或许 AI 可以直接生吃,但是坚持反混淆也算是一种老一辈艺术家的坚守。
间接跳转 且先看一段调用的 BinaryNinja 的 LLIL SSA form 的调用地址计算逻辑
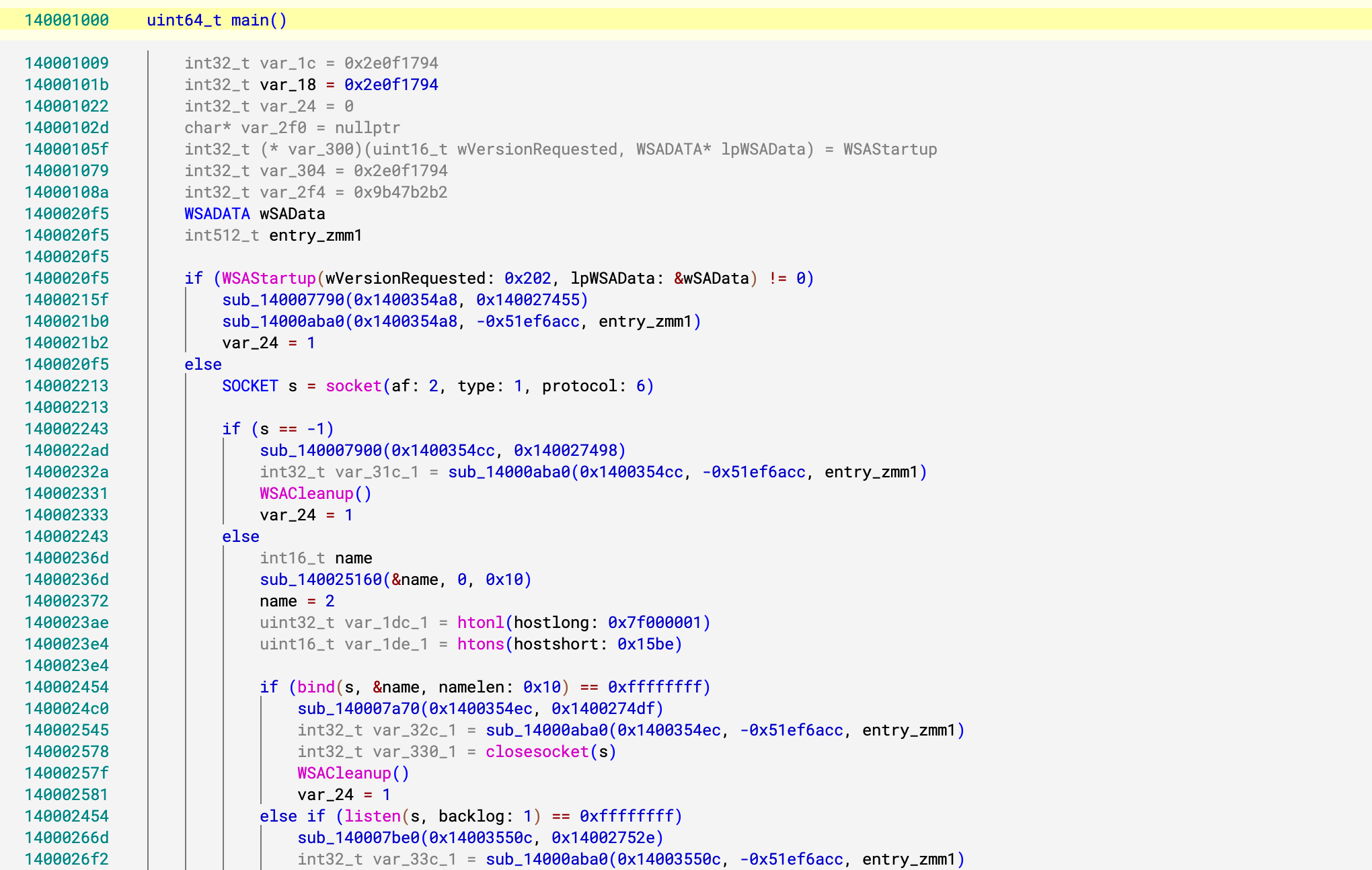
5 @ 140001009 [rsp#3 + 0x41c {var_1c}].d = 0x2e0f1794 @ mem#2 -> mem#3 6 @ 140001014 rax#1 = zx.q([rsp#3 + 0x41c {var_1c}].d @ mem#3) 24 @ 140001079 [rsp#3 + 0x134 {var_304}].d = rax#1.eax @ mem#7 -> mem#8 33 @ 1400010aa cond:0#1 = temp0#1.d s< -0x231bebc0 34 @ 1400010af rcx#6 = zx.q(0xd) 35 @ 1400010b4 rdx#6 = zx.q(0x2f) 36 @ 1400010b9 if (cond:0#1) then 37 else 39 @ 0x1400010bc 37 @ 1400010b9 rdx#7 = zx.q(rcx#6.ecx) 38 @ 1400010b9 goto 39 @ 0x1400010bc 39 @ 1400010bc rdx#8 = ϕ(rdx#6, rdx#7) 40 @ 1400010bc r8#4 = [&data_140033c28].q @ mem#12 41 @ 1400010c3 rcx#7 = zx.q(0xdc1facc8) 42 @ 1400010c8 r9#5 = zx.q([rsp#3 + 0x134 {var_304}].d @ mem#12) 43 @ 1400010d0 rcx#8 = zx.q(rcx#7.ecx - r9#5.r9d) 44 @ 1400010d3 r10#2 = sx.q(rcx#8.ecx) 45 @ 1400010d6 r8#5 = r8#4 + r10#2 46 @ 1400010d9 r10#3 = zx.q(rdx#8.edx) 47 @ 1400010dc r8#6 = [r8#5 + (r10#3 << 3)].q @ mem#12 48 @ 1400010e0 rcx#9 = zx.q(0xa92f1d1c) 49 @ 1400010e5 rcx#10 = zx.q(rcx#9.ecx - r9#5.r9d) 50 @ 1400010e8 r10#4 = sx.q(rcx#10.ecx) 51 @ 1400010eb r8#7 = r8#6 + r10#4 ❓ 52 @ 1400010ee jump(r8#7) => r8#7 = [r8#5 + (r10#3 << 3)].q + (0xa92f1d1c - var_304) = [r8#5 + (ϕ(0xd, 0x2f) << 3)].q + (0xa92f1d1c - var_1c)
其中 r8#5 的计算逻辑我们先不展开,反正他就是个跳转表的基地址,所以这样看其实就很直观了,本质上就是 DestBBs[idx] + (X - MySecret) 对应的正是 llvm/lib/Transforms/Obfuscation/IndirectBranch.cpp 中的下面的内容
其中 var_1c 对应 MySecret
Value *MySecret; if (SecretInfo) { MySecret = SecretInfo->SecretLI; } else { MySecret = ConstantInt::get(Type::getInt32Ty(Ctx), 0 , true ); }
if (BI && BI->isConditional()) { IRBuilder<> IRB(BI); Value *Cond = BI->getCondition(); Value *Idx; Value *TIdx, *FIdx; TIdx = ConstantInt::get(Type::getInt32Ty(Ctx), BBNumbering[BI->getSuccessor(0 )]); FIdx = ConstantInt::get(Type::getInt32Ty(Ctx), BBNumbering[BI->getSuccessor(1 )]); Idx = IRB.CreateSelect(Cond, TIdx, FIdx); Value *GEP = IRB.CreateGEP(DestBBs, {Zero, Idx}); LoadInst *EncDestAddr = IRB.CreateLoad(GEP, "EncDestAddr" ); Constant *X; if (SecretInfo) { X = ConstantExpr::getSub(SecretInfo->SecretCI, EncKey); } else { X = ConstantExpr::getSub(Zero, EncKey); } Value *DecKey = IRB.CreateSub(X, MySecret); Value *DestAddr = IRB.CreateGEP(EncDestAddr, DecKey); IndirectBrInst *IBI = IndirectBrInst::Create(DestAddr, 2 ); IBI->addDestination(BI->getSuccessor(0 )); IBI->addDestination(BI->getSuccessor(1 )); ReplaceInstWithInst(BI, IBI); }
间接函数调用 先看一段调用的 BinaryNinja 的 LLIL SSA 形式的调用地址 r9#3 的计算逻辑
5 @ 140001009 [rsp#3 + 0x41c {var_1c}].d = 0x2e0f1794 @ mem#2 -> mem#3 6 @ 140001014 rax#1 = zx.q([rsp#3 + 0x41c {var_1c}].d @ mem#3) 10 @ 140001039 rcx#1 = [&data_140033c20].q @ mem#6 11 @ 140001040 rdx#1 = zx.q(0xdc1facc8) 12 @ 140001045 r8#1 = zx.q(rdx#1.edx) 13 @ 140001048 r8#2 = zx.q(r8#1.r8d - rax#1.eax) 14 @ 14000104b r9#1 = sx.q(r8#2.r8d) 15 @ 14000104e rcx#2 = [rcx#1 + r9#1].q @ mem#6 16 @ 140001052 rdx#2 = zx.q(rdx#1.edx - rax#1.eax) 17 @ 140001054 r9#2 = sx.q(rdx#2.edx) 18 @ 140001057 rcx#3 = rcx#2 + r9#2 20 @ 14000105f [rsp#3 + 0x138 {var_300}].q = rcx#3 @ mem#6 -> mem#7 23 @ 140001071 r9#3 = [rsp#3 + 0x138 {var_300}].q @ mem#7 => r9#3 = rcx#2 + (0xdc1facc8 - var_1c)
其中 r8#5 的计算逻辑我们先不展开,它就是 EncDestAddr,在 llvm/lib/Transforms/Obfuscation/IndirectCall.cpp 中的生成逻辑如下,
Value *Idx = ConstantInt::get(Type::getInt32Ty(Ctx), CalleeNumbering[CS.getCalledFunction()]); Value *GEP = IRB.CreateGEP(Targets, {Zero, Idx}); LoadInst *EncDestAddr = IRB.CreateLoad(GEP, CI->getName());
因为 Idx 是个绝对的常量,所以编译器优化会直接把 &Targets[Idx] 的地址整个计算出来 Load,把 EncDestAddr 当成一个全局变量,这里看不到 Targets[Idx] 的逻辑。
不难发现,上面的 rcx#2 + (0xdc1facc8 - var_1c) 刚好对应 EncDestAddr + (X - MySecret)
Value *Secret = IRB.CreateSub(X, MySecret); Value *DestAddr = IRB.CreateGEP(EncDestAddr, Secret); Value *FnPtr = IRB.CreateBitCast(DestAddr, FTy->getPointerTo()); FnPtr->setName("Call_" + Callee->getName()); CallInst *NewCall = IRB.CreateCall(FTy, FnPtr, Args, Call->getName());
间接全局变量引用 前文中省去了 DestBBs 和 EncDestAddr 的展开,现在回到这个问题,
5 @ 140001009 [rsp#3 + 0x41c {var_1c}].d = 0x2e0f1794 @ mem#2 -> mem#3 6 @ 140001014 rax#1 = zx.q([rsp#3 + 0x41c {var_1c}].d @ mem#3) 24 @ 140001079 [rsp#3 + 0x134 {var_304}].d = rax#1.eax @ mem#7 -> mem#8 40 @ 1400010bc r8#4 = [&data_140033c28].q @ mem#12 41 @ 1400010c3 rcx#7 = zx.q(0xdc1facc8) 42 @ 1400010c8 r9#5 = zx.q([rsp#3 + 0x134 {var_304}].d @ mem#12) 43 @ 1400010d0 rcx#8 = zx.q(rcx#7.ecx - r9#5.r9d) 44 @ 1400010d3 r10#2 = sx.q(rcx#8.ecx) 45 @ 1400010d6 r8#5 = r8#4 + r10#2 => DestBBs = r8#5 = [&data_140033c28].q + (0xdc1facc8 - var_304) = [&data_140033c28].q + (0xdc1facc8 - var_1c)
5 @ 140001009 [rsp#3 + 0x41c {var_1c}].d = 0x2e0f1794 @ mem#2 -> mem#3 6 @ 140001014 rax#1 = zx.q([rsp#3 + 0x41c {var_1c}].d @ mem#3) 10 @ 140001039 rcx#1 = [&data_140033c20].q @ mem#6 11 @ 140001040 rdx#1 = zx.q(0xdc1facc8) 12 @ 140001045 r8#1 = zx.q(rdx#1.edx) 13 @ 140001048 r8#2 = zx.q(r8#1.r8d - rax#1.eax) 14 @ 14000104b r9#1 = sx.q(r8#2.r8d) 15 @ 14000104e rcx#2 = [rcx#1 + r9#1].q @ mem#6 => EncDestAddr = rcx#2 = [[&data_140033c20].q + (0xdc1facc8 - var_1c)]
都刚好对应 EncGVAddr + (X - MySecret)
if (GlobalVariable *GV = dyn_cast<GlobalVariable>(*op)) { if (GVNumbering.count(GV) == 0 ) { continue ; } IRBuilder<> IRB(Inst); Value *Idx = ConstantInt::get(Type::getInt32Ty(Ctx), GVNumbering[GV]); Value *GEP = IRB.CreateGEP(GVars, {Zero, Idx}); LoadInst *EncGVAddr = IRB.CreateLoad(GEP, GV->getName()); Constant *X; if (SecretInfo) { X = ConstantExpr::getSub(SecretInfo->SecretCI, EncKey); } else { X = ConstantExpr::getSub(Zero, EncKey); } Value *Secret = IRB.CreateSub(X, MySecret); Value *GVAddr = IRB.CreateGEP(EncGVAddr, Secret); GVAddr = IRB.CreateBitCast(GVAddr, GV->getType()); GVAddr->setName("IndGV" ); Inst->replaceUsesOfWith(GV, GVAddr); }
过程相关特性 经过前面几处的分析,不难发现几乎 goron 中的每一种混淆都离不开 MySecret 这个值,对于上面分析的 main 函数这种可能被外界(非用户编写代码)的函数,MySecret 的值是定义在函数内部的,对于一定由用户定义代码调用的函数 MySecret 通过函数的第一个参数传递。比如样本中的 sub_140005c70,其 MySecret 从 [rcx#0].d 处初始化(也就是函数的第一个参数)。
9 @ 140005c7b rax#1 = zx.q([rcx#0].d @ mem#4) 10 @ 140005c7d [rsp#5 + 0x120 {var_28}].d = rax#1.eax @ mem#4 -> mem#5 26 @ 140005ce2 [rsp#5 + 0xe8 {var_60}].d = rax#1.eax @ mem#10 -> mem#11 69 @ 140005db7 cond:0#1 = temp0#1.d s< -0x4a34b609 70 @ 140005dbc rcx#6 = zx.q(0x11) 71 @ 140005dc1 rdx#10 = zx.q(2) 72 @ 140005dc6 if (cond:0#1) then 73 else 75 @ 0x140005dc9 73 @ 140005dc6 rdx#11 = zx.q(rcx#6.ecx) 74 @ 140005dc6 goto 75 @ 0x140005dc9 75 @ 140005dc9 rdx#12 = ϕ(rdx#10, rdx#11) 76 @ 140005dc9 r8#10 = [&data_140033da8].q @ mem#21 77 @ 140005dd0 rcx#7 = zx.q(0x6c7f5c1c) 78 @ 140005dd5 r9#6 = zx.q([rsp#5 + 0xe8 {var_60}].d @ mem#21) 79 @ 140005ddd rcx#8 = zx.q(rcx#7.ecx - r9#6.r9d) 80 @ 140005de0 r10#7 = sx.q(rcx#8.ecx) 81 @ 140005de3 r8#11 = r8#10 + r10#7 82 @ 140005de6 r10#8 = zx.q(rdx#12.edx) 83 @ 140005de9 r8#12 = [r8#11 + (r10#8 << 3)].q @ mem#21 84 @ 140005ded rcx#9 = zx.q(0xdff33be4) 85 @ 140005df2 rcx#10 = zx.q(rcx#9.ecx - r9#6.r9d) 86 @ 140005df5 r10#9 = sx.q(rcx#10.ecx) 87 @ 140005df8 r8#13 = r8#12 + r10#9 ❓ 88 @ 140005dfb jump(r8#13)
BinaryNinja 反混淆思路 BinaryNinja 提供了 Workflow API 可以在反编译流程中修改 IL 代码。修改 IL 代码,不像 patch 汇编需要考虑空间够不够,状态寄存器有没有被覆盖...这些鸡零狗碎,复杂至极的问题迎刃而解。
后文中提到的 functionKey,对应的就是前面分析 goron 源码时出现的 MySecret。
“过程相关” 对抗 这个样本最麻烦的地方,不是某一种单独的混淆,而是几乎所有混淆都和过程内的 functionKey 绑定在一起。间接跳转依赖它,间接函数调用依赖它,间接全局变量引用依赖它,控制流平坦化里的状态初始化也依赖它。只要这个值还是脏的,后面所有地址相关表达式都会跟着脏掉。
首先对当前样本来说,哪些函数需要 functionKey、functionKey 是什么,分析者是很容易知道的,先把这个输入显式提供出来。对于这个问题,我的做法是通过 metadata.eat_shit.functionKey 为函数提供对应的 functionKey 值,再单独加一个 func_key_pass,在 LLIL SSA 层先把函数入口对 functionKey 的读取改成常量。这样后续无论是前端分析里的栈初始化收集、间接跳转恢复,还是 workflow 中的常量折叠与控制流恢复,处理的都是已经被修正过的 IL。
间接跳转恢复 间接跳转恢复是一切的基础。当前样本里很多真实代码块都挂在间接跳转后面,BinaryNinja 如果不知道跳转目标,连 CFG 都搭不出来,函数边界也会跟着乱掉。在这种状态下,别说在 Workflow 里 patch IL,大部分基本块 BinaryNinja 压根都不认为它们是代码。
所以第一步不是急着 patch jump(reg),而是先算出它的两个真实目标,然后调用 set_user_indirect_branches 把用户分支信息喂给 BinaryNinja,先把 CFG 恢复出来。只有 CFG 先恢复出来,BinaryNinja 才能把这些目标块重新纳入函数,Workflow 里的 pass 也才能继续在正确的函数范围上工作。
目标求解本身还是基于 LLIL SSA 反向切片。最终落点表现为 jump(reg),在 SSA 里顺着 reg 的定义链往回追,就可以还原出目标地址的计算表达式。于是问题就变成了:给定分支条件取真和取假两种环境,最终的跳转表达式各自会算出什么地址。
做法比较直接:
从当前 jump(reg) 出发,做一份反向切片。
在切片中定位真正控制分支的 SSA 定义。
分别模拟分支取真、取假时的环境。
计算出 T0 和 T1 两个目标地址。
先调用 set_user_indirect_branches 恢复 CFG。
再在 Workflow 里把这个间接跳转 patch 成 if goto。
这样拆成两步之后,事情就顺了。前一步解决“让 BN 知道这些边存在”,后一步解决“把 IL 改成更好分析的形式”。对当前样本,main 里恢复了数十个间接跳转,sub_140005c70 里也恢复了十几个;做到这一步后,函数图才真正从“断掉的碎块集合”变成一个还能继续反编译的函数。
间接全局变量引用、间接函数调用 恢复 间接全局变量引用和间接函数调用,本质上都是同一类问题:原来应该直接出现的地址,被改写成了 EncAddr + (X - MySecret) 这种依赖过程内 key 的表达式。只要 key 已经在前面的 func_key_pass 里被常量化,这一类表达式后面就都可以交给常量传播去吃。
这里注意到,无论是间接全局变量引用还是间接函数调用,最终如果做“强力的常量折叠”(不考虑 data 段可写),得到的常量一定是一个指针,指向当前程序的某个段。所以,这里并没有针对它们的规则做匹配简化,而是统一交给 constant_fold_pass 在 LLIL SSA 层递归求值,把所有能稳定折叠成 section pointer 的表达式直接替换成 CONST_PTR。一旦替换成功,BinaryNinja 自己就会把它重新识别成更正常的调用目标、全局变量引用或跳转表地址。
这样做的关键前提有两个:
functionKey 已经先被 patch 成常量。已经把完整的函数边界恢复出来。
控制流平坦化恢复
这一部分整体思路部分参考了葫芦娃前辈的文章 深入 OBPO 还原控制流的核心原理
前面的几个 pass 做完之后,剩下最难看的部分就是控制流平坦化。这里我没有走“从入口一路模拟到函数结束”的路线,而是先把问题拆成三个更具体的问题:
哪些块属于 dispatcher?
每个 state 对应的 case head 是哪个块?
每个 case 最终会把状态改成什么,然后跳回哪个 dispatcher?
dispatcher 识别 当前实现里,dispatcher 的识别标准很克制:
块尾是 MLIL_IF
条件表达式最终可以规约成“状态变量的无副作用派生值”和“常量”的比较
这里“无副作用派生值”只支持一小组非常保守的表达式:
VARZX / SX / LOW_PART一层 PHI
ADD / SUB / XOR 常量
目的不是做一个完整解释器,而是只接受当前样本里足够稳定的状态表达式,让状态传播仍然是可解释、可验证的。
状态到 case 的映射 做法上,先从入口走到第一个 dispatcher,执行 prologue,把初始状态算出来;再沿 dispatcher 的条件判断传播 state 集合,把“某个具体 state 会落到哪个 case head”恢复出来。
case 后继恢复 case 出口恢复是从 case head 出发递归遍历后继块;某条路径一旦进入其他 case 的入口块,就认为它已经离开当前 case,不再继续;如果路径重新回到 dispatcher,就把这条路径上最近一次状态写回对应的值记成这个 case 的 successor。
这样就可以把:
入口 goto dispatcher
case 内部的“写状态然后回 dispatcher”
分支 case 的“分别写两个状态再回 dispatcher”
统一改写成 case 到 case 的直接边。BinaryNinja 重新生成 MLIL / HLIL 后,原本那层 dispatcher 就会被撕掉,控制流重新回到正常可读的结构上。
结果与总结 最终反混淆效果如下,剩下字符串加密没有处理,终归是一个 CTF 题,这种程度的字符串加密大家肯定都是一脚踢死就没必要再专门写一下了。
代码基本都是 AI 编写的,就不掏出来献丑了 应群友要求现开放源代码 https://github.com/GaoYuCan/eat_shit
面向 x86_64 架构下的 goron 混淆框架设计,属于纯 vibecoding 的实验性代码,仅用于研究和学习。